










ঘৃণাত্মক বক্তব্য যা একবার ব্যক্তিগতভাবে প্রচারিত হয়েছিল এখন পর্দার পিছনে বেনামী অনলাইন অ্যাকাউন্টগুলির মাধ্যমে আরও দ্রুত এবং দ্রুত ভ্রমণ করে৷
যেমন জাতিসংঘ চিহ্নিত করে আন্তর্জাতিক দিবস 18 জুন ঘৃণাত্মক বক্তৃতা প্রতিরোধের জন্য, জাতিসংঘের মহাসচিব আন্তোনিও গুতেরেস সতর্ক করেছেন যে সামাজিক প্ল্যাটফর্মগুলি হুমকিকে আরও বাড়িয়ে তুলছে৷
কৃত্রিম বুদ্ধিমত্তার (AI) সাথে ক্রমবর্ধমানভাবে অনলাইনে ঘৃণাত্মক বক্তব্য সনাক্তকরণ এবং অপসারণের দায়িত্ব দেওয়া হয়েছে, আল জাজিরা মানুষের বিচারের তুলনায় এই সিস্টেমগুলি কোথায় কম পড়ে তা দেখে।
ঘৃণামূলক বক্তব্য কিভাবে সংজ্ঞায়িত করা হয়?
জাতিসংঘের মতে, ঘৃণাত্মক বক্তৃতা যে কোনো যোগাযোগকে কভার করে – কথ্য, লিখিত বা আচরণগত – যা কোনো ব্যক্তি বা গোষ্ঠীর প্রতি বৈষম্য বা সহিংসতাকে উস্কে দেয়।
জাতিসংঘ বলেছে যে ঘৃণামূলক বক্তব্য একজন ব্যক্তির প্রকৃত বা অনুভূত পরিচয়, জাতি, জাতি, ধর্ম, লিঙ্গ, যৌন অভিমুখীতা বা অক্ষমতাকে লক্ষ্য করে। এবং এটি কেবল শব্দের মধ্যে সীমাবদ্ধ নয়, জাতিসংঘের উল্লেখ করে এটি চিত্র, কার্টুন, অঙ্গভঙ্গি এবং এমনকি বস্তুর আকারও নিতে পারে।
কতজন লোক অনলাইনে ঘৃণামূলক বক্তব্যের সম্মুখীন হয়?
অনুযায়ী ক 2023 পোলিং সংস্থা ইপসোস এবং ইউএন এডুকেশনাল, সায়েন্টিফিক অ্যান্ড কালচারাল অর্গানাইজেশন (ইউনেস্কো) দ্বারা 16টি দেশের 8,000 জন মানুষের যৌথ সমীক্ষা, ইন্টারনেট ব্যবহারকারীদের দুই-তৃতীয়াংশেরও বেশি অনলাইনে ঘৃণামূলক বক্তব্যের সম্মুখীন হয়েছে৷
সমীক্ষায় আরও দেখা গেছে যে 33 শতাংশ লোক ভেবেছিল যে এলজিবিটিকিউআই লোকেরা সবচেয়ে বেশি ঘৃণাত্মক বক্তব্যের অভিজ্ঞতা অর্জন করেছে, তারপরে জাতিগত ও জাতিগত সংখ্যালঘুরা (28 শতাংশ) এবং মহিলারা (18 শতাংশ)।
মেটা, যা ফেসবুকের মালিক, 2023 সাল থেকে কম ঘৃণ্য পোস্ট সরিয়েছে। 2025 সালের শেষ ত্রৈমাসিকে, সংস্থাটি Instagram থেকে 1.3 মিলিয়ন এবং Facebook থেকে 1.3 মিলিয়ন পোস্ট সরিয়ে দিয়েছে, যেখানে 2024 সালের চতুর্থ ত্রৈমাসিকে Instagram থেকে 7.4 মিলিয়ন এবং Facebook থেকে 5.8 মিলিয়ন পোস্ট মুছে ফেলা হয়েছে।
কোম্পানিটি ঘৃণাত্মক বক্তব্যের সক্রিয় সনাক্তকরণ থেকে দূরে সরে যাওয়ায় এবং এনকাউন্টার রিপোর্ট করার জন্য ব্যবহারকারীদের উপর বেশি নির্ভর করে।
অন্যদিকে, টিকটক বলেছেন এটি রিপোর্ট করার আগে 2025 এর চতুর্থ ত্রৈমাসিকে সমস্ত ঘৃণাত্মক বক্তব্য এবং সামগ্রীর 96.3 শতাংশ সরিয়ে দিয়েছে৷
এআই মডেলগুলি ঘৃণামূলক বক্তব্যকে ভিন্নভাবে সনাক্ত করে
অনলাইনে ঘৃণাত্মক বক্তব্যের বিস্তার শনাক্ত করতে এবং মোকাবেলা করতে, সোশ্যাল মিডিয়া কোম্পানিগুলি ক্রমবর্ধমানভাবে AI-এর দিকে ঝুঁকছে, বৃহৎ ভাষা মডেল (LLMs) দ্বারা চালিত সামগ্রী মডারেশন সিস্টেমগুলি ব্যবহার করে যা বিপুল পরিমাণ বার্তা জুড়ে সামগ্রী ফিল্টারিং স্বয়ংক্রিয় করার প্রতিশ্রুতি দেয়৷
সাধারণভাবে, এই সিস্টেমগুলি আপত্তিজনক ভাষা সনাক্ত করতে লেবেলযুক্ত ডেটাসেট এবং পূর্বপ্রশিক্ষিত ভাষা মডেল ব্যবহার করে। বিষয়বস্তু ঘৃণ্য বা কোম্পানির নীতি লঙ্ঘন করে কিনা তা সিদ্ধান্ত নিতে তারা তারপর নিয়ম বা স্কোর থ্রেশহোল্ড প্রয়োগ করে।
একটি 2025 অধ্যয়ন পেনসিলভানিয়া বিশ্ববিদ্যালয়ের গবেষকরা দেখেছেন যে এই মডেলগুলি কীভাবে তারা ঘৃণাত্মক বক্তৃতা শনাক্ত করে এবং শ্রেণিবদ্ধ করে তার মধ্যে ব্যাপকভাবে পরিবর্তিত হয়, সিস্টেম এবং জনসংখ্যার গোষ্ঠীগুলিতে উল্লেখযোগ্য অসঙ্গতি রয়েছে, অনলাইনে পক্ষপাত এবং অসম সুরক্ষা সম্পর্কে উদ্বেগ বাড়ায়৷
গবেষণায় সাতটি এআই মডারেশন সিস্টেমের মূল্যায়ন করা হয়েছে – যার মধ্যে রয়েছে OpenAI, Anthropic, DeepSeek, Mistral, এবং Google-এর মডেল এবং তারা কীভাবে বিভিন্ন বিভাগ জুড়ে ঘৃণাত্মক বক্তব্য শনাক্ত করেছে এবং স্কোর করেছে তার মধ্যে বড় পার্থক্য খুঁজে পেয়েছে।
এই চার্টটি দেখায় যে কীভাবে বিভিন্ন এআই মডারেশন সিস্টেম 0-1 স্কেলে একই গোষ্ঠীকে লক্ষ্য করে ঘৃণামূলক বক্তব্যের তীব্রতা স্কোর করেছে। উচ্চতর মানগুলি নির্দেশ করে যে মডেলটি বিষয়বস্তুটিকে আরও ঘৃণ্য বলে বিচার করেছে৷
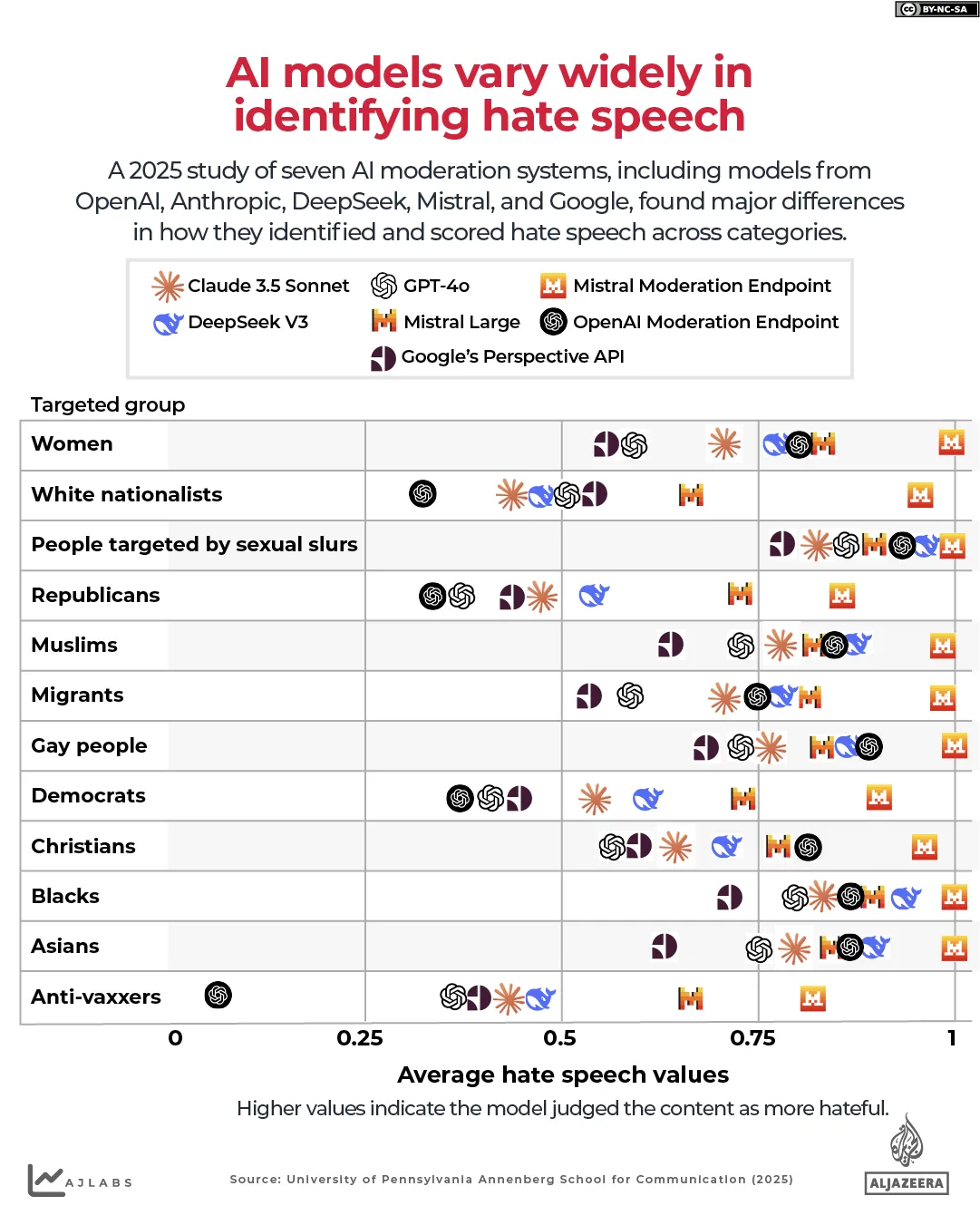
মিস্ট্রাল মডারেশন এন্ডপয়েন্ট প্রায়ই 1 এর খুব কাছাকাছি ক্লাস্টার করা হয়, যার অর্থ এটি লক্ষ্য গোষ্ঠী নির্বিশেষে অনেকগুলি উদাহরণকে অত্যন্ত ঘৃণ্য হিসাবে লেবেল করে।
ওপেনএআই মডারেশন এন্ডপয়েন্ট অনেক বিভাগের জন্য অনেক কম স্কোর তৈরি করে, কখনও কখনও অন্যান্য মডেল দ্বারা নির্ধারিত স্কোরের অর্ধেকেরও কম।
অধ্যয়নের লেখকরা যেমন বলেছেন, “যদি দুটি সিস্টেম একই বিষয়বস্তুর জন্য ভিন্ন ফলাফল তৈরি করে – এটিকে একটি ক্ষেত্রে ঘৃণাত্মক বক্তব্য হিসাবে ফ্ল্যাগ করা কিন্তু অন্য ক্ষেত্রে নয় – এটি সংযম প্রক্রিয়ার বৈধতাকে দুর্বল করে।”
এআই ঘৃণাত্মক বক্তব্য সনাক্তকরণের সীমাবদ্ধতা
যদিও AI সিস্টেমগুলি স্পষ্ট ঘৃণাত্মক বক্তব্য সনাক্ত করতে সক্ষম হয় – উদাহরণস্বরূপ, যখন একটি নির্দিষ্ট গোষ্ঠীর বিরুদ্ধে অশ্লীলতা এবং গালি ব্যবহার করা হয় – আরও সূক্ষ্ম উদাহরণ এলএলএমগুলি মিস করে।
“একটি চ্যালেঞ্জিং উদাহরণ হল অন্তর্নিহিত ঘৃণাত্মক বক্তৃতার ঘটনা, যা প্রায়শই সনাক্ত করা যায় না কারণ এতে স্লারের কোন উল্লেখ নেই,” লন্ডনের কুইন মেরি ইউনিভার্সিটির একজন সহযোগী অধ্যাপক এবং বিশ্ববিদ্যালয়ের সোশ্যাল ডেটা সায়েন্স ল্যাবের সহ-প্রধান আর্কাইৎজ জুবিয়াগা আল জাজিরাকে বলেছেন। “এটি একটি ইতিবাচক-শব্দযুক্ত বার্তার ক্ষেত্রে হতে পারে যেমন “আমি দেখতে চাই যে পৃথিবী কতটা মহান হবে যদি…” এর পরে একটি জনতাত্ত্বিক গোষ্ঠীকে অপমান করে একটি অবমাননাকর বার্তা আসে৷ AI সিস্টেমগুলি সেই বার্তাগুলিতে ঘৃণা দেখতে সংগ্রাম করতে পারে যদি তারা বার্তাটির ইতিবাচক দিকের দিকে মনোনিবেশ করে।”
জুবিয়াগা যোগ করেছেন যে বিপরীতটিও সত্য, যেখানে আপাতদৃষ্টিতে আপত্তিকর শব্দগুলি, যা এখন আরও প্রিয় উদ্দেশ্যে ভাষায় অন্তর্ভুক্ত করা হয়েছে, ঘৃণামূলক বক্তব্য হিসাবে হাইলাইট করা হয়েছে।
“এটি পুনরুদ্ধার করা ভাষার ক্ষেত্রে, যেখানে ঐতিহাসিকভাবে অপমানজনক বলে মনে করা কীওয়ার্ডগুলিকে গ্রহণ করা হয় এবং সেই সম্প্রদায়গুলি দ্বারা পুনরায় ব্যবহার করা হয় যেগুলিকে তারা প্রথমে অপমান করার জন্য ব্যবহার করা হয়েছিল, এবং তারপরে প্রান্তিক সম্প্রদায়ের সদস্যদের মধ্যে স্লারগুলি ব্যবহার করা হয়,” তিনি বলেছিলেন। “যদিও এই কেসগুলিকে ঘৃণ্য হিসাবে চিহ্নিত করা উচিত নয়, এআই সিস্টেমগুলির এটি করার প্রবণতা রয়েছে।”
(ট্যাগসটোঅনুবাদ
international




